人工智能(AI)技术是数字经济的核心驱动力。各国政府均在布局 AI 领域的全栈能力,并出资引导建设智能算力基础设施。我国也已进入智能化时代。“十四五”期间,各部委积极推动智能计算中心(简称智算中心)的建设和发展,旨在为 AI 应用提供公共算力服务。智算中心是以 GPU 等智能计算芯片为核心、集约化建设的新型算力基础设施,提供软硬件全栈环境,主要承载模型训练、集中推理和多媒体渲染等业务,支撑各行业数智化转型升级。生成式人工智能(AIGC)可谓是现阶段最热门的AI 大模型。AIGC 的前身是 OpenAI 公司发布的通用人工智能网络 GPT3,拥有 1 750 亿个参数量和 45 TB的预训练数据量,其后基于 GPT3 发布商业化产品ChatGPT。ChatGPT 可以回答问题、写诗、作词,甚至可以创作论文、音乐和电视剧等,在部分领域的能力甚至超越人类的基准水平。AI 大模型计算主要包含模型预训练、模型微调和模型推理 3 个步骤。模型预训练阶段进行算法架构搭建,基于大数据集对模型进行自监督式训练,生成基础大模型 ;模型微调阶段基于小数据集和 RLHF 等对模型进行调优和对齐,生成行业大模型或垂类模型 ;模型推理阶段基于用户调用需求,输出计算结果。GPT 类 AI 大模型属于大规模语言模型,参数量巨大,对算力的需求呈指数级的增长。训练模型所需的时间与消耗的资源成反比,训练时长越短,所需消耗的资源量越大。据估算,3 个月内训练出一个 GPT3 模型,需要消耗 3 000 多张单卡算力不小于 300 TFLOPS(半精度 FP16)的 GPU 卡,而如果想在 1 个月内训练出GPT3 模型,则需要 10 000 多张同类型 GPU 卡。同时,推理此类模型也无法在 1 张 GPU 卡进行,最少需要 8卡同时进行推理才能保证延迟在 1 秒以内。随着语言类模型的大获成功,相关技术方法被引入图像、视频和语音等多个应用场景。如构建用于目标检测和图像分类等的视觉类大模型,可广泛应用于自动驾驶和智慧城市等领域。多模态大模型可以同时覆盖众多场景,与此同时,参数规模进一步迅速增长,可达百万亿级别,对智算中心的算力、数据和网络等能力提出了更高的要求。GPU 芯片按形态可以分为 PCIe 标卡和扣卡模组两种。两种形态的 GPU与 CPU之间通信均通过 PCIe总线。CPU 会参与训练中的数据集加载和处理等工作,主要差异在于 GPU 的卡间通信方式和卡间互联带宽不同。对于大多数标准的服务器来讲,受服务器 PCIe 总线设计和插槽数量的限制,通常 1 台服务器内部最多可以部署 8 张 GPU 芯片。采用 PCIe 标卡形态的 GPU 芯片,服务器内部 8 卡之间通过 PCIe Switch 进行连接。PCIe Switch 是一种用于拓展 PCIe 接口的芯片,可以实现 1 个 PCIe 接口对接多个 PCIe 设备,1 台部署 8 张 GPU 卡的服务器,1 个 PCIe Switch 可以对接 4 张 GPU 卡,服务器设置 2 个 PCIe Switch 可以实现 8张卡的互联通信。采用 PCIe 4.0 协议,卡间双向带宽为 64 Gbit/s ;采用 PCIe 5.0 协议,卡间双向带宽为 128 Gbit/s。具体卡间通信方式根据业务场景和部署的模型不同,有 3 种模式可选,具体如图 1 所示。
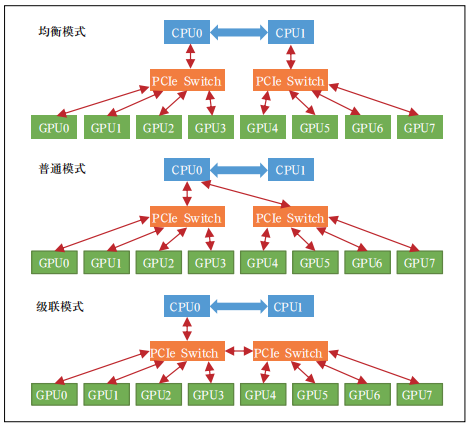
第 1 种为均衡模式。PCIe Switch 分别通过 2 个 CPU 进行连接,远端 GPU 卡之间通过 PCIe Switch 跨 CPU 进行通信。这种模式下,CPU 利用率最大化,可以提供更大的上行链路带宽,但远端卡间通信受限于 CPU 之间的 UPI 通信带宽。均衡模式可以保证每个 GPU 的性能均衡,适用于公有云场景,以及 CPU 和 GPU 同时参与任务的算法模型,如 Inception3 等。第 2 种 为 普 通 模 式。PCIe Switch 通 过 同 一 个CPU 进行连接,远端 GPU 卡之间无需跨 CPU 之间进行 UPI 通信,可以提供较大的点对点卡间带宽,并且 CPU 到 GPU 之间有 2 条 PCIe 通道,吞吐量高。普通模式可以提供较好的 GPU 与 CPU 之间的通信性能,适用于 CPU 参与较多任务的通信密集型算法模型,如Resnet101 和 Resnet50 等。第 3 种为级联模式。PCIe Switch 不通过 CPU 直接连接,远端 GPU 卡之间直接通过 PCIe Switch 级联通信,点对点卡间带宽最大,但 CPU 到 GPU 之间只有 1 条 PCIe 通道,吞吐量相对较小。级联模式可以为大参数量模型提供最优的点对点卡间通信性能,适用于CPU 参与较少任务的计算密集型算法模型,如 VGG-16 等。PCIe 标卡服务器机型主要用于单机单卡或单机多卡训练场景。3 种卡间通信模式支持按需配置,对 CPU核心数和虚拟化要求较高的云化场景通常选用均衡模式。在分布式训练场景下,不同算法模型选用合适的通信模式可获得最优的 GPU 线性加速比,在有限条件下可实现 GPU 卡的最大化利用。采用扣卡模组形态的 GPU 芯片,服务器内部的 8张卡集成在 1 块基板上,GPU 卡间可以实现端到端全互联。扣卡模组服务器机型搭配外部的高速互联网络可有效满足大规模的多机多卡并行训练任务。扣卡模组基板主要分为 SXM 和 OAM 两种标准。SXM 是独家私有标准,需要配合私有的 NVLink 接口实现卡间高速互联 ;OAM 是开放模组标准,对外提供标准接口,打破对独家的供应依赖。OAM 提供的接口具有高度灵活性,卡间互联可有多个变种拓扑结构。NVLink 是为解决 PCIe 总线带宽限制提出的一种 GPU 互连总线协议。目前 NVLink协议演进到第 4 代,每张 GPU 最大支持 18个 NVLink 连接,GPU 卡之间双向带宽可达900 Gbit/s。PCIe 标卡服务器可通过选配 NVLink 桥接器,实现相邻 2 张卡之间的高速互联,采用桥接器可实现的最高双向带宽为 600 Gbit/s。但 NVLink 桥接器无法实现服务器内部所有 GPU 卡之间的全互联,在大模型训练场景下仍无法满足多机多卡之间的并行通信需求。采用 NVLink 桥接器的卡间互联架构示意如图 2 所示。
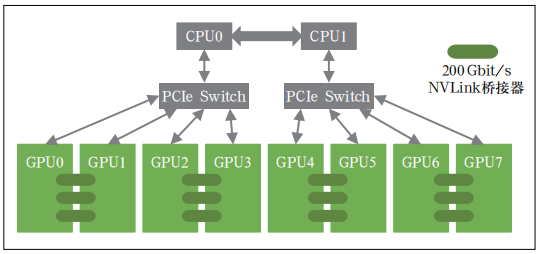
图2 PCIe标卡采用NVLink桥接器的卡间互联架构示意图SXM 扣卡模组是芯片厂商自有设计标准,基板不仅集成了 8 张 GPU 卡,同时还集成了 NVSwitch 芯片,每个 NVSwitch(第 4 代)都有 64 个 NVLink 网络端口,可以将 8 张 GPU 卡全部连接起来,是实现 8 卡之间端到端全互联的关键组件。卡间互联架构示意如图 3 所示。
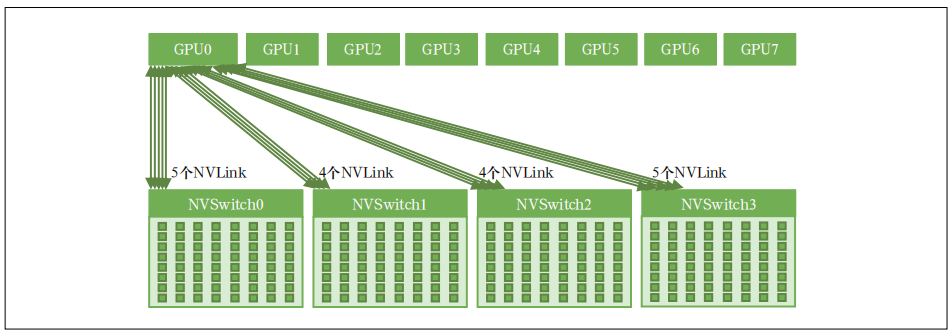
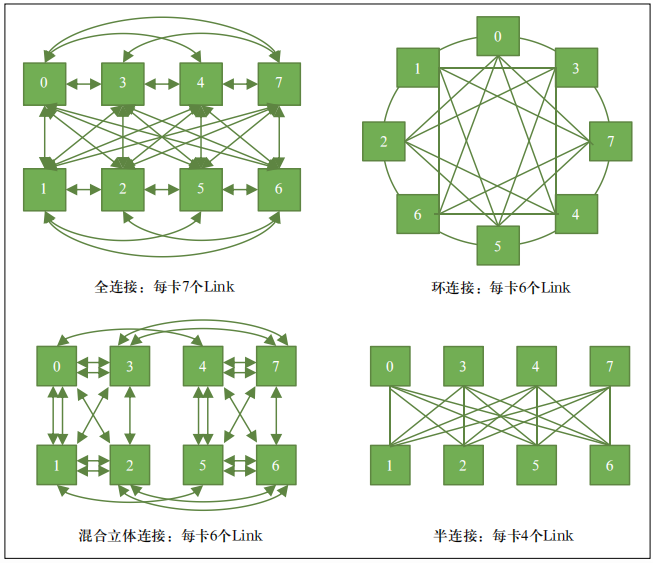
OAM 是开源组织 OCP 定义的用来指导 GPU 模组系统设计的标准。其对标 SXM 模组,可以帮助 GPU服务器实现更好的类似 NVLink 的卡间互联通信。目前国产 GPU 服务器普遍采用 OAM 扣卡模组形态。OAM 标准定义了 GPU 服务器内部的扣卡模组、主板、机箱、供电、制冷、I/O 交互和系统管理等一系列规范。不同厂商设计的扣卡模组只要符合 OAM 标准,卡间互联通信有多种方案可以灵活选择。典型的有全连接、混合立体连接、环连接和半连接等。卡间互联架构示意如图 4 所示。OAM除了需要考虑卡间互联链路以外,还需要同步考虑与 CPU、网卡等部件的连接,以及预留对外的扩展端口。全连接是未来趋势,但当前国产 GPU 芯片产品设计定位和方式不同,多采用混合立体连接和半连接方式。
当前,AI 大模型逐步由单模态向多模态转变,涉及视觉问答、情感分析、跨媒体检索和生成任务等多种应用场景。多模态模型算法更加复杂、数据规模更加庞大。扣卡模组形态的 GPU 芯片,卡间互联通信不受 PCIe 接口带宽限制,可提供更高的卡间带宽和更低的传输时延,在多模态大模型训练应用中可以提供更出色的性能。扣卡模组机型和 PCIe 标卡机型的整机服务器散热方式选型需结合服务器功耗情况、内部构造特点和服务器整机厂家支持情况综合决定。首先,扣卡模组机型功耗较高,PCIe 标卡机型功耗相对较低,配置 8 卡的扣卡模组机型整机功耗约为7 ~ 11 kW,而 PCIe 标卡机型整机功耗约为 3 ~ 4 kW。其次,扣卡模组插卡在同一个平面上,更适合冷板结构设计,而 PCIe 标卡采用独立竖插方式,每个插卡需要单独设计冷板,且冷板间互联结构复杂。另外,从厂家支撑情况来看,扣卡模组机型整机服务器厂家大多具备液冷方案,而 PCIe 标卡机型的整机服务器厂家液冷方案较少。液冷散热方式又分为冷板式液冷和浸没式液冷两种,具体差异见表 1。
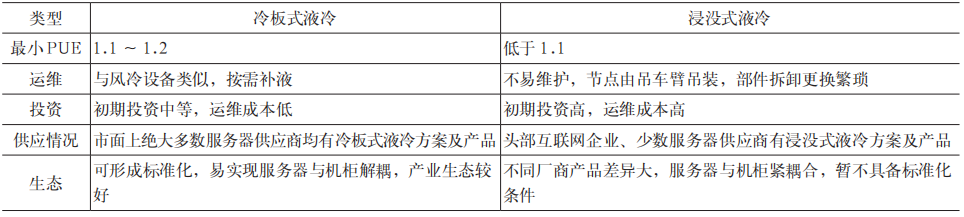
相较浸没式液冷技术,当前冷板式液冷在初始投资成本、网络运维模式、生态成熟度、机房改造难度和工程实施进度等方面更具有优势。同时,冷板式液冷服务器存在整机柜交付和服务器与机柜解耦交付两种方式,具体差异见表 2。

考虑液冷技术特点、竞争生态和运维界面等问题,在尚未建立机柜解耦标准的情况下,更适合选择整机柜交付方式。综上分析,PCIe 标卡机型采用风冷散热方式即可满足使用需求,使用数据中心通用机柜安装,无需整机柜配置。扣卡模组机型需采用液冷散热方式,结合当前技术和生态情况,优选冷板式液冷和整机柜交付模式。智算中心在大模型训练、AI+ 视频、自动驾驶和智慧城市等业务场景都有较大的智能算力需求和发展空间。目前国内智算中心建设如火如荼,全国有 30 多个城市已建成或正在建设智算中心。但建设智算中心与传统云计算平台不同,在计算、存储、网络、应用、平台等各方面都有较高要求和挑战,后续将持续关注并研究智算全栈技术,为建设技术领先、绿色节能、服务全局的大型智算中心提供可行性方案。
原文刊载于《电信工程技术与标准化》 2024年1月 作者:张鹏飞 田雯 武振宇 贾凡 刘长瑞 施子墨
声明:本文系转载,旨在分享,版权归原作者所有,内容为原作者个人观点,并不代表本网赞同其观点和对其真实性负责。如涉及作品版权问题,请与我们联系,我们将在第一时间删除内容!
