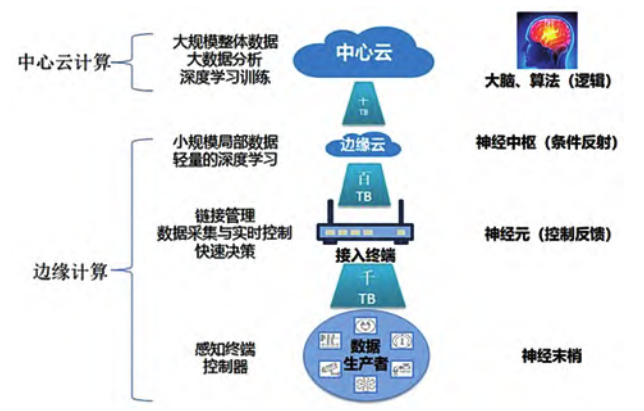
随着工业数字化、智能化转型逐渐深入,智能制造的逐步推进,市场对于工业机器视觉的需求也将逐渐增多,工业机器视觉逐渐形成规模化的产业。机器视觉主要用计算机来模拟人的视觉功能,也就是把客观事物的图像信息提取、处理并理解,最终用于实际检测、测量和控制。机器视觉具有高度自动化、高效率、高精度和适应较差环境等优点,将在我国工业自动化的实现过程中产生重要作用。在工业领域,机器视觉对计算的高效性有严格的要求,将数据传输至云端计算可能无法满足高效实时的需求,同时考虑到在工业现场中存在大量异构的总线连接,设备之间的通信标准不统一,需要将计算资源部署在工业现场附近才能满足需求,边缘计算成为了关键节点,起到了重要的作用。工业机器视觉目前在智能制造中主要用于四个方面:识别、检测、识别和测量。传统机器学习算法使用人工输入的特征提取代码来训练算法,而深度学习算法使用现代技术自动提取这些特征。深度学习算法在视觉图像分类、语义分割、目标检测、显著性检测等任务上取得了很高的准确性 , 甚至超过人的认知水平。深度学习技术的引入以后,人工调试的研究大大减少。因为深度学习可以很好的解决视觉图像轮廓影像检测,虽然深度学习还无法保证其100%可靠性,但是可以通过技术手段已经可以实现相当高的可靠性。近年来,伴随着大数据、云计算、人工智能的发展,互联网产业即将面临巨大的变革。大数据时代每天的数据量十分巨大,而物联网环境因为地理位置分散,对响应时间和安全性要求更高。现今云计算虽然为大数据处理提供一个很好的平台,但网络速度远远赶不上数据增长的速度,网络带宽的问题需要硬件上跨时代的突破才能解决,云计算模式在边缘端很难满足实时性和带宽要求。在云计算难以满足边缘端计算的需求背景下,边缘计算应运而生。边缘计算是指在互联网边缘上计算和存储资源,它可以选择性接入互联网。这个网络边缘在地理上和网络上都接近用户。边缘计算可以在数据源附近进行处理,这样能很好保护数据安全性,同时还能增加响应实时性。边缘计算分析将复杂算法模型从云端下沉到边缘,对生产现场数据进行实时分析和反馈控制,可以在没有网络连接的情况下处理数据。终端无需传输在网络边缘收集到的所有数据,而是在本地或者更靠近数据源的地方处理数据,这有助于避免严重的“最后一公里”延迟问题。对于需要快速决策的终端,在本地处理数据可以让它们做出更快的响应。此外,通过本地分析,可以将仅仅相关的数据发送回云服务器来减轻网络负载。云平台则将实现海量工业数据统一集成管理,提供信息模型、数据治理机制、数据共享、数据标识以及数据可视化等全流程的操作和服务。
在云端定义基础数据模型,将模型下发到各边缘服务器,边缘服务器对数据模型通过业务接口下发到工业视觉终端上。终端在收到数据模型后,根据数据模型对采集的本地图像数据进行识别、检测和测量,获取信息特征,将特征值以及加工过数据上传至边缘服务器。边缘服务器对所管理的工业视觉终端数据进行汇总,加工数据以及信息发送至云端服务平台。云端服务平台通过对数据进行提纯,对移动终端相关的硬件信息,状态信息,软件信息,关联的用户信息以及生产数据等等,将流程问题抽象成领域模型问题,再将领域模型抽象成数据模型。工业视觉识别系统在电子制造行业中的应用,电子制造生产线多样,工艺复杂,工业视觉主要应用于3C电子检测、显示屏检测与线路板检测,形成从部件模组到整机的闭环检测,其中3C电子检测更为复杂。通过预先在边缘端设置训练好缺陷识别模型,在流水线通过机器视觉缺陷检测,及时计算匹配出贴装过程产生的元器件装反、漏装、装错、位置不准确等问题。

工业视觉识别系统在钢铁工业中的应用,钢筋数量统计(计数)是钢材生产过程中的重要环节。钢筋经过打捆以后,现场的计数工人主要使用不同颜色的彩笔来多次标记以区分已计数和未计数的钢筋,对于工人长时间高强度的工作,其视觉和大脑很容易出现疲劳,计数误差大大增加,很明显人工计数已经不能满足钢筋生产厂家自动化生产的需求。因此,研发钢筋数量统计(计数)多目标检测机器视觉方法是一个十分迫切且重要的问题,对减轻人工工作劳动强度,提高钢筋数量统计的效率和准确性具有重要作用。将工业视觉系统固定在生产线上,当信号触发时将拍摄图像直接输出到边缘端,控制器进行识别计算后直接输出钢筋数量。

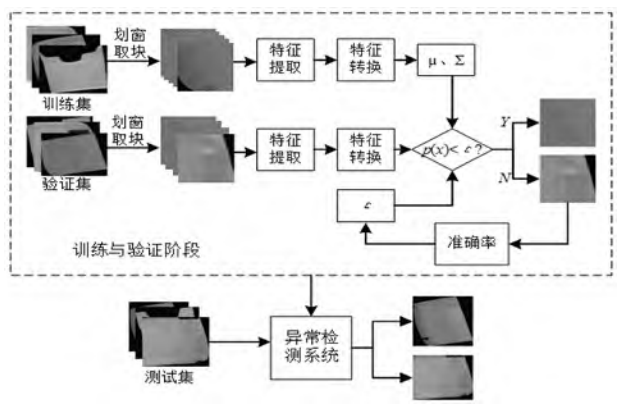
人工智能的定义是让机器实现原来只有人类才能完成的任务。机器学习专门研究计算机怎样模拟或实现人的学习行为,是人工智能的核心。通过机器学习的重要方法深度学习,通过对大量图像的识别训练,反复调整模型参数,获取目标需求所需的训练模型。考虑到工业生产环节不良品占比少、图像数据收集困难的现状,本项目拟研究无监督学习的异常检测,将少量不良品与大量良品区别开来,获取不良品数据再进行人工标注。
近年,深度模型的压缩和加速一直是学术界、工业界的研究热点,可以将体积庞大的深度模型压缩至极小。最新的人脸检测深度模型在基本达到主流算法性能的同时,已经能够压缩至1MB大小,最新的目标检测算法YOLO nano也压缩到了5MB以内,能够满足嵌入式平台的要求。在端末设备上优化AI算法,设计友好的边缘计算硬件方案,是边缘计算最关键的技术问题。深度学习在人工智能领域取得了重大突破,但高存储高功耗的深度网络模型,严重制约了在硬件资源有限环境下的使用,需要对模型进行压缩。目前,卷积神经网络(CNN)的压缩算法大多是针对卷积的某一特性进行研究或基于其他辅助的基础上进行研究。然而,这些方法可能导致CNN模型准确率的快速下降,或局限于较小的CNN模型和大型数据集到小型数据集的迁移学习上,无法得到更为广泛的应用。采用基于动态阈值的网络权重剪裁,为了保证裁剪网络压缩率和准确率的平衡,采用迭代裁剪的方法,根据权重绝对值大小进行网络的裁剪,即寻找最合适的权重,让剪裁后的模型损失与未剪裁的模型损失尽量一致。考虑到网络中各层的权重及其分布各不相同,因此对每一层分别进行裁剪,权重裁剪流程如下:(1)取一个较小的初始裁剪率,根据该层的权重分布进行裁剪,将权重最小的一部分进行裁剪;(2)对裁剪后的网络进行正则化微调训练,获得裁剪后的模型准确率,再计算剪裁前后模型准确率的差值;(3)若裁剪前后模型准确率差值小于设定好的阈值,则增加裁剪率,返回第一步;否则,结束裁剪。通过对庞大且冗余模型的裁剪,在有限的性能下,提高边缘计算的运行效率,满足工业机器视觉系统的需求。AI边缘计算用于工业视觉识别场景,在性能改善、减少操作成本和保障数据安全上有一定优势。工业制造中常见的状态跟踪、缺陷检测、零件定位等需求,在工业生产环境中边缘计算设备可在生成和使用数据的视觉终端处理与存储数据,而无需将数据传到遥远的数据中心,如此可以保证响应的实时性、更低的成本、结合分布式存储和边缘智能计算将进一步提高隐私数据的安全性等。通过AI与边缘计算的在工业视觉识别系统中的深度结合,将大幅提高生产自动化水平,装备的使用效率、可靠性及稳定性等。
来源:新工业网
声明:本文系转载,旨在分享,版权归原作者所有,内容为原作者个人观点,并不代表本网赞同其观点和对其真实性负责。如涉及作品版权问题,请与我们联系,我们将在第一时间删除内容!
